
Bridging the Data Gap for Computer-Use Agents
Modern LLMs read the internet but still stumble through basic software workflows. That gap comes down to data and evaluation. At Paradigm Shift AI, we"re tackling both.
Who We Are
Paradigm Shift AI is building the data and evaluation layer for computer-use agents.
Our human-in-the-loop pipeline captures human-computer interaction (HCI) data:
| Layer | What You Get |
|---|---|
| Video | Full-resolution screen-recordings |
| Events | Mouse + keyboard + app logs |
| Metadata | OS system metadata |
| Optional | Reasoning steps, GUI boxes, DOM, a11y trees |
The result? Clean, structured datasets ready for model training, fine-tuning, RLHF, or benchmarking.
TL;DR: If an agent needs to see, click, and think like a real user, we give you the ground truth.
Inside Our 1,000-Task Pilot
We just wrapped a 1,000 real-world task pilot covering everyday computer workflows like editing docs and spreadsheets, tweaking OS settings, online shopping, data analysis, and more.
Grab 30 Sample Tasks
Kick the tires on our data and explore the raw files yourself: Download the 30-tasks sample →
Demo: Use Google Lens to identify and find where to buy a product online.
Our pilot tasks capture real human workflows with full context. This example shows how a user completes a product search using Google Lens, with all interactions recorded.
Each task includes screen recordings, event logs, screenshots, and reasoning steps - providing a complete picture of human problem-solving that AI agents can learn from.
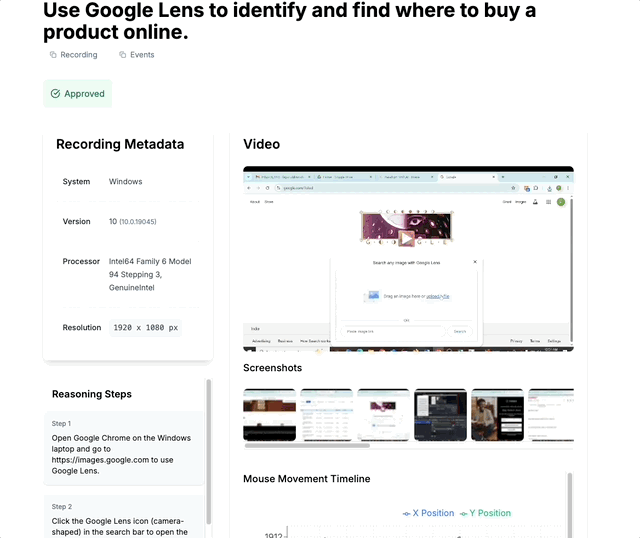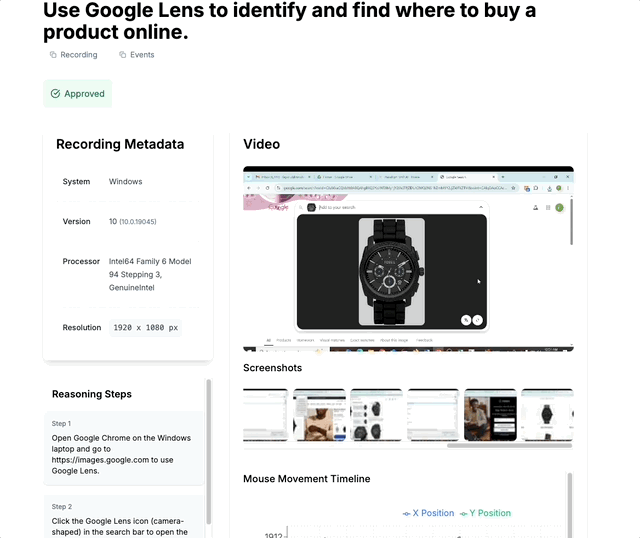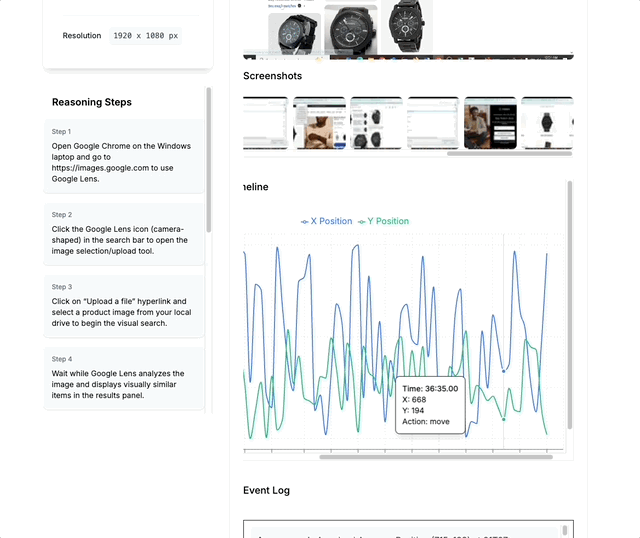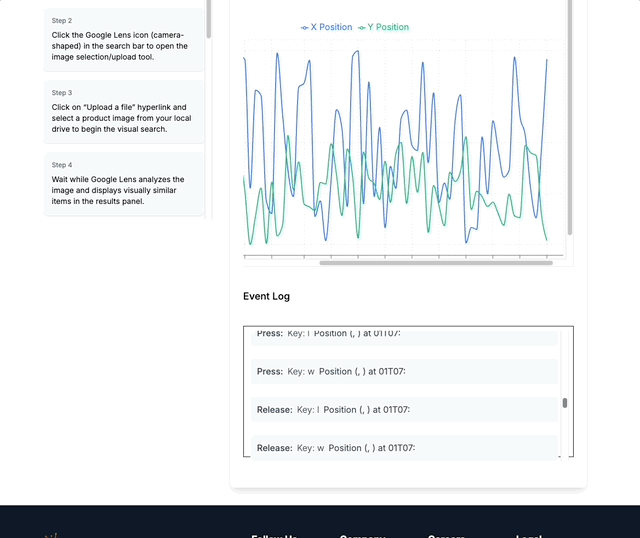
(Pilot task with screen recording, event logs & screenshots and reasoning steps)
Coming Soon: Disposable-VM Simulation Platform
Data alone isn"t enough; teams need a fast way to measure gap-to-human performance. We"re finalizing a simulation platform that spins up disposable VMs, executes an agent on a predefined task script, and scores it against our human baseline—complete with replayable failure traces
- Spins up a disposable VM
- Runs your computer-use agent through a task script
- Scores it against our human baseline (✓ / ✗ timeline, error traces)
- Returns replayable failure logs for rapid debugging
Early testers are already queued up. Want early access?
Let"s Talk
If you"re:
- Building or fine-tuning computer-use agents
- Searching for high-fidelity HCI data
- Looking to benchmark agents against real-world workflows
- Curious about our upcoming agent evaluation simulator
📩 Email us at info@paradigm-shift.ai and we"ll set up a demo.
Quick Links
Paradigm Shift AI — The data & evaluation layer your agents have been waiting for.